
回顧一下 ETL Pipeline 中間那一塊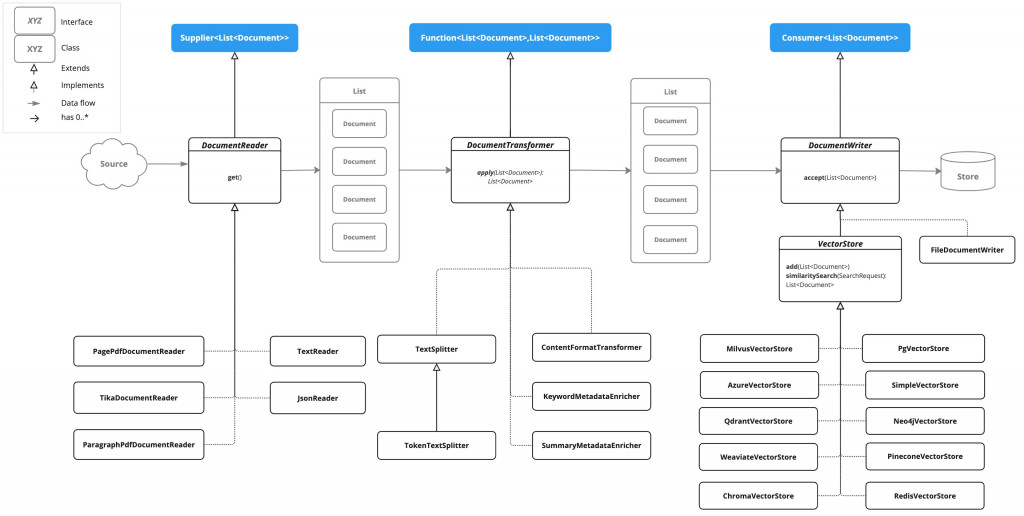
前面只用到 TokenTextSplitter 將大檔案切成小塊,今天來詳細的介紹這些工具有甚麼功用以及詳細的參數設定
前面用過預設的標準拆分,他還有個帶參數的建構子
TokenTextSplitter(int
defaultChunkSize, int minChunkSizeChars, int minChunkLengthToEmbed, int
maxNumChunks, boolean keepSeparator)
defaultChunkSize :每個文字區塊的目標大小(以 Token 為單位)(預設值:800)。minChunkSizeChars :每個文字區塊的最小字元數(預設值:350)。minChunkLengthToEmbed:要嵌入的區塊的最小長度(預設值:5)。maxNumChunks :從內容產生的最大區塊數(預設值:10000)。keepSeparator :是否在區塊中保留分隔符號(如換行符)(預設值:true)。
一般使用預設切割即可,想優化查詢結果在自行調整參數測試
它能使用 AI 模型從文件內容中提取關鍵字,並將其添加為 metadata。剛開始以為這是甚麼黑科技,竟然能自己列出關鍵字,沒想到只是一個提示詞就能做到,下面是原始碼使用的提示詞
public static final String KEYWORDS_TEMPLATE = """
{context_str}. Give %s unique keywords for this
document. Format as comma separated. Keywords: """;
修改昨天匯入 pdf 的程式碼
EtlService.java
private final ChatModel chatModel;
//從Document中取得10個關鍵字
List<Document> keywordDocuments(List<Document> documents) {
KeywordMetadataEnricher keywordEnricher = new KeywordMetadataEnricher(chatModel, 10);
return keywordEnricher.apply(documents);
}
public List<Document> loadPdfAsDocuments() throws IOException {
ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
Resource[] resources = new Resource[0];
resources = resolver.getResources("./pdf/*.pdf");
List<Document> docs = new ArrayList<>();
for (Resource pdfResource : resources) {
try {
ParagraphPdfDocumentReader pdfReader = new ParagraphPdfDocumentReader(pdfResource);
docs.addAll(pdfReader.read());
} catch (IllegalArgumentException e) {
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader(pdfResource);
docs.addAll(pdfReader.read());
}
}
return docs;
}
public void importPdf() throws IOException {
TokenTextSplitter splitter = new TokenTextSplitter();
vectorStore.write(splitter.split(keywordDocuments(loadPdfAsDocuments())));
}
這一個串一個的程式有沒有像嵌套俄羅斯娃娃XD
看看測試結果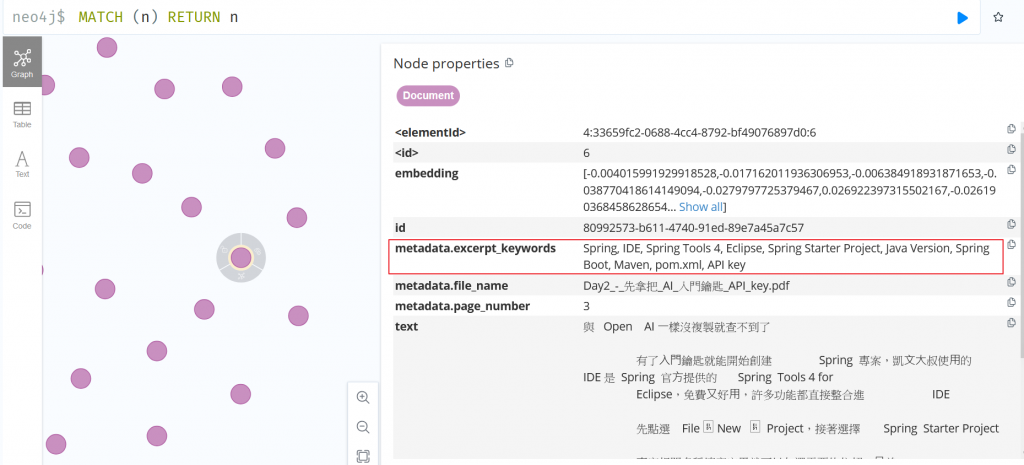
這功能其實就是進階 RAG 的方法之一,透過關鍵字強化 embedding 數值,讓近似搜尋更為精準,另外也可作為推薦字或是進階篩選的功能
它使用 AI 模型為文件建立摘要並新增為 metadata,它可以為當前 Document 以及相鄰 Document(上一個和下一個)產生摘要。
一樣先看一下原始碼中如何寫提示詞
public static final String DEFAULT_SUMMARY_EXTRACT_TEMPLATE = """
Here is the content of the section:
{context_str}
Summarize the key topics and entities of the section.
Summary:""";
看起來也沒多複雜,學習程式內如何使用模板也是不錯的方式
EtlService.java: 一樣寫一個 summaryDocuments 函式,在加進拆分程式中
List<Document> summaryDocuments(List<Document> documents) {
SummaryMetadataEnricher summaryEnricher = new SummaryMetadataEnricher(chatModel,
List.of(SummaryType.PREVIOUS, SummaryType.CURRENT, SummaryType.NEXT));
return summaryEnricher.apply(documents);
}
public void importPdf() throws IOException {
TokenTextSplitter splitter = new TokenTextSplitter();
vectorStore.write(splitter.split(summaryDocuments(keywordDocuments(loadPdfAsDocuments()))));
}
老實說這樣寫有點陷入嵌套地獄了,之後應該會改成 Advisor 的寫法
一樣直接看結果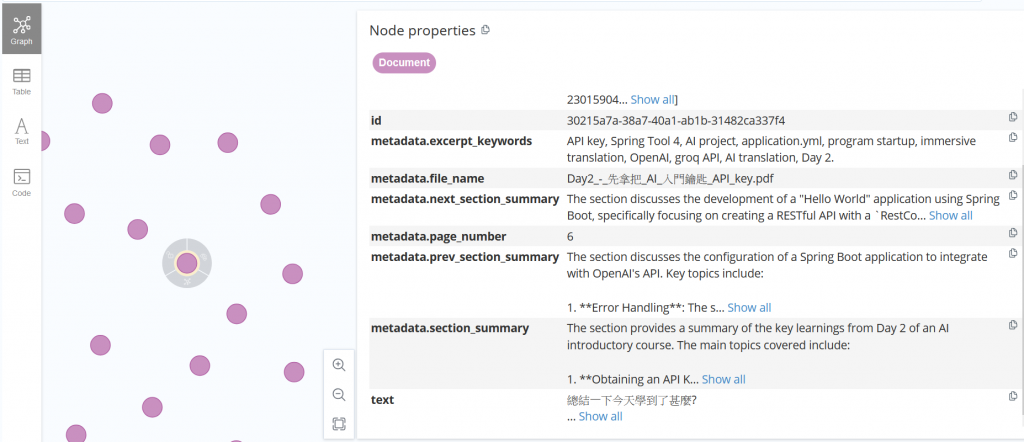
除了上個範例的 metadata.excerpt_keywords,還多了三個摘要,內容分別如下
metadata.section_summary: The section provides a summary of the key learnings from Day 2 of an AI introductory course. The main topics covered include:
- Obtaining an API Key: Instructions on how to acquire an API key necessary for accessing AI services.
- Creating an AI Project in Spring Tool 4: Guidance on setting up an AI project using the Spring Tool 4 development environment.
- Configuring the API Key in application.yml: Steps to integrate the obtained API key into the project's configuration file (application.yml) for successful program startup.
- Immersive Translation: A discussion on custom immersive translation features compatible with OpenAI's API, specifically mentioning the ability to use the groq API for free AI translation services.
Overall, the section emphasizes practical skills for working with AI projects and utilizing APIs effectively.
metadata.prev_section_summary: The section discusses the configuration of a Spring Boot application to integrate with OpenAI's API. Key topics include:
- Error Handling: The section begins with an error log indicating a
BeanCreationExceptiondue to a missing OpenAI API key, which is necessary for the application to function properly.- Configuration Setup: It explains how to set the API key in the
application.ymlfile, detailing the necessary structure for the configuration:
- The key should be placed under
spring: ai: openai: api-key: {your_api_key}.- It also mentions setting the chat model to
gpt-4o-minifor cost-effective performance.- Successful Initialization: After configuring the API key, the application starts successfully without errors, demonstrating that the automatic configuration and bean creation for
openAiChatModelis functioning correctly.- Alternative Integration with Groq: The section suggests that users who may not have credits for OpenAI can utilize Groq as an alternative. It provides a similar configuration structure but uses Groq's API key and base URL (
https://api.groq.com/openai), along with a different model (llama-3.1-70b-versatile).Overall, the key entities include Spring Boot, OpenAI, API keys, application configuration, and the models used for AI interaction.
metadata.next_section_summary: The section discusses the development of a "Hello World" application using Spring Boot, specifically focusing on creating a RESTful API with a
RestController. Key topics include:
- Spring Boot: A framework used for building web applications in Java.
- Hello World: A common introductory example in programming.
- RestController: An annotation that indicates the class is a controller for handling RESTful web services.
- API Development: The process of creating an application programming interface to enable communication between different software components.
- ChatClient: A component presumably used to interact with a chat service.
- 自動注入 (Automatic Injection): A mechanism in Spring for automatically injecting dependencies into classes.
- 錯誤 (Error): An issue encountered when the application fails to find a required Bean during execution.
- Bean: An object managed by the Spring IoC (Inversion of Control) container.
- Controller: A component that handles incoming requests and returns responses.
The section emphasizes the simplicity of starting a Spring Boot application and highlights an error encountered related to dependency management.
這摘要還蠻長的,若之後想使用這功能建議可以自訂提示詞,並在提示詞中限制字數上限,自訂提示詞須改用下面建構子
SummaryMetadataEnricher(ChatModel chatModel, List<SummaryType> summaryTypes, String summaryTemplate, MetadataMode metadataMode)
參數說明如下chatModel :用於產生摘要的 AI 模型。summaryTypes:一個SummaryType枚舉值列表,表示要產生 Document 的 前一個(PREVIOUS)、目前(CURRENT)、下一個(NEXT) 摘要,預設是全部都產生。
摘要與關鍵字都是用來加強 embedding 的準確性,也都是進階 RAG 常用的方法,另外其結果使用英文也會讓 AI 更容易判讀
今天學到了甚麼?
程式碼下載: https://github.com/kevintsai1202/SpringBoot-AI-Day27.git
凱文大叔使用 Java 開發程式超過 20 年,對於 Java 生態非常熟悉,曾使用反射機制開發 ETL 框架,對 Spring 背後的原理非常清楚,目前以 Spring Boot 作為後端開發框架,前端使用 React 搭配 Ant Design
下班之餘在 Amazing Talker 擔任程式語言講師,並獲得學員的一致好評
最近剛成立一個粉絲專頁-凱文大叔教你寫程式 歡迎大家多追蹤,我會不定期分享實用的知識以及程式開發技巧
想討論 Spring 的 Java 開發人員可以加入 FB 討論區 Spring Boot Developer Taiwan
我是凱文大叔,歡迎一起加入學習程式的行列

